

上周,大概全中国的云技术人才都聚在深圳,因为AmazonWeb Services (AWS) 技术峰会9月20日在深圳举行。
上周,大概全中国的云技术人才都聚在深圳,因为 AmazonWeb Services (AWS) 技术峰会 9 月 20 日在深圳举行。
作为 AWS 技术峰会 2018 中国行的收官之作,本场峰会汇集多位 AWS 高管和技术专家,分享 AWS 在物联网、移动技术、人工智能、大数据等领域的创新与展望;亦有本土技术型企业代表,分享成功案例及实践经验。
Mobvista 作为技术驱动型的全球领先移动营销平台,由技术副总裁兼首席架构师蔡超、资深后端研发工程师梁晓鹏出席峰会并做专题技术演讲,分享 Mobvista 在搭建和完善云计算体系过程中的经验。

蔡超,Mobvista 技术副总裁兼首席架构师
以下为蔡超所作的《云端俭省之道》演讲分享。
——————
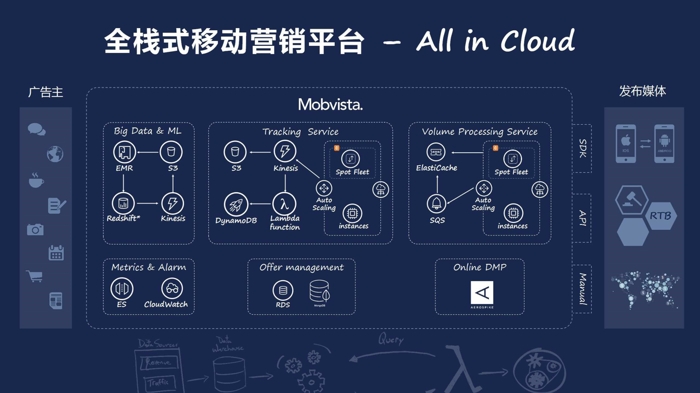
Mobvista 的宗旨是「建立覆盖全球每一个人的信息输送管道」,公司建立了覆盖全球的移动营销平台,通过平台助力移动开发者利用全球优质广告资源来实现高效的流量变现,同时帮助广告主利用全球优质流量资源实现广告的精准投放。
从一开始,Mobvista 就考虑到业务的快速启动、规模的快速扩展及全球化,所以我们的整个系统和平台都建立在云端。
Mobvista 成立于 2013 年,经过短短几年的发展时间,我们已经成为中国最大、全球前十的移动营销平台,我们的日触达用户已达 9 亿,日均的请求数量目前已经接近 400 亿。
如同每一个在云端搭建大规模系统的公司一样,规模的快速增长,带来的是成本的快速增长的压力。这也是为什么我加入到 Mobvista,如果你参加了去年的 ArchSummit2017,那你会知道我去年是代表亚马逊来做一些 session 的分享的。
在这半年的时间里面,我们通过架构的优化,以及利用 AWS 的一些新技术来逐渐降低我们的成本,通过半年的优化,我们实现了单位请求的成本降低了约60%,这是一个非常难以置信的结果。那下面,我会分享一些我们自己的实践,供大家参考。
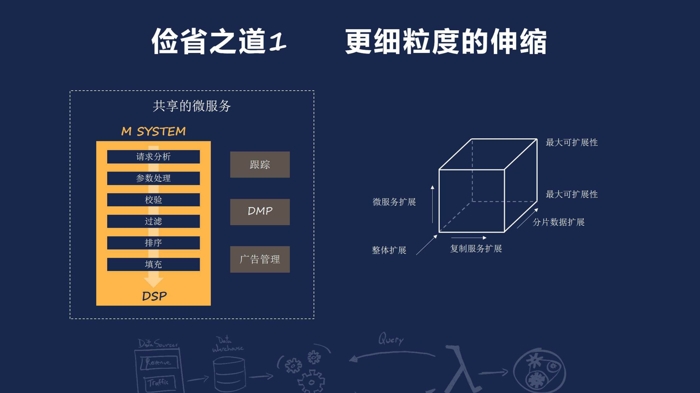
第一个非常重要的,就是在你的架构层面实现更细粒度的伸缩,以往的单体系统在伸缩的时候我们是通过两种方式,第一种是复制系统服务,第二就是对数据进行分片。通常情况下系统的瓶颈不会是在于系统的所有方法,往往只是在于某一个方法,那这样的方式由于会导致整个系统的复制使用更大的硬件资源,导致一些硬件资源的浪费,那如果你采用微服务的话,你可以实现更细粒度的伸缩,那么对于处于瓶颈状态的微服务进行单独的伸缩、单独的复制,对它所使用的数据进行分片,提高硬件的使用效率。
另一方面,利用 AWS Lambda 技术,你可以直接将计算方法或业务方法上传至云端,直接进行计算或运行,而无需考虑其承载器的硬件以及扩充硬件的规模。AWS Lambda 将根据请求量变化实现自动伸缩。同时,使用 AWS 提供的 Backend Service,例如存储、步骤编排(data pipeline)等,你可以完整地构建一个 Serverlessarchitecture。
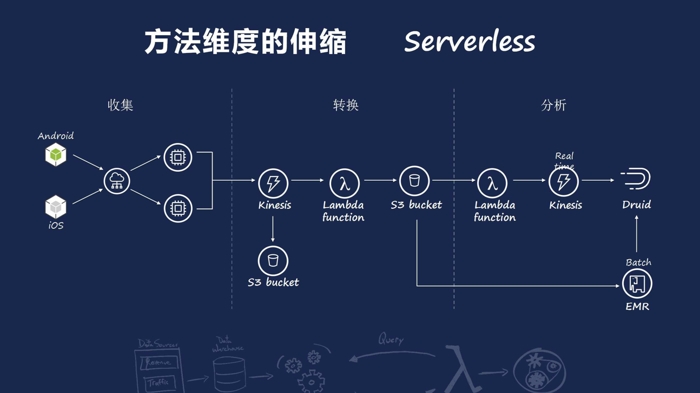
上图是我们的一个游戏数据统计系统,这个游戏数据统计系统也是覆盖全球。我们可以看一下,整体的架构中没有任何一台主机。Serverless 不仅降低了系统的硬件成本,更加降低了硬件的维护成本(关于这方面更多的分享,欢迎大家参加下午我的同事梁晓鹏——公司资深工程师的一个关于 Serverless 的 session。)
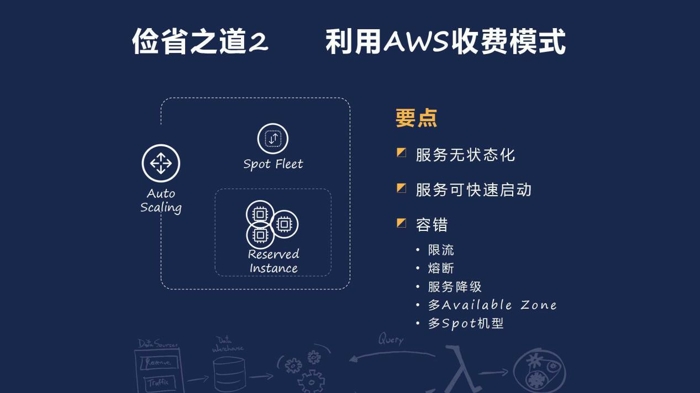
第二,就是充分利用 AWS 的收费模式。AWS 推出了 Spot Instance,这是一种闲置的 EC2Instance,通常你可以以 1-1.5 折的价格来获取 Spot Instance,但是在某些资源紧张的情况下以及在你的竞价低于市场价的情况下,这些 Instance 会被回收掉。如果你的应用可以实现 InstanceFlexible、同时你精巧的设计还可以满足到以上这些容错特性,那么你可以结合 AutoScaling 以及混合一部分的 OnDemand 和 Reserved Instance 来实现一个可靠并且低成本的系统。
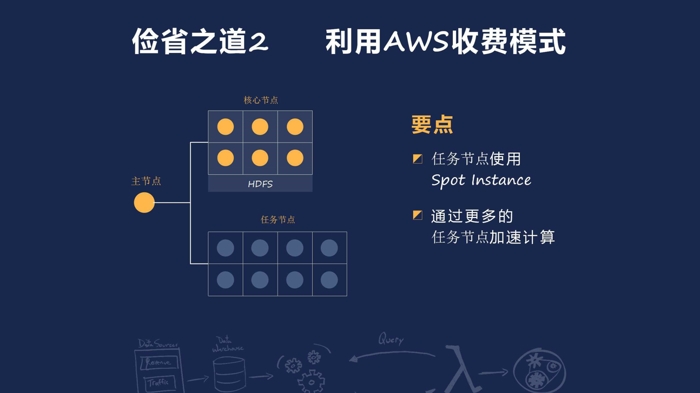
不仅是 Online 系统,对于后台的大数据平台,如果是使用 AWS EMR 平台,你同样可以利用 SpotInstance 来降低你的成本。我们可以用 SpotInstance 来运行 TaskNode,TaskNode 在失效时,EMR 平台会对它进行重新运行。与 Master Node 和 Core Node 不同的是,TaskNode 的失效并不会引起整个 EMR 平台的失效,也不会像引起很大的 data shuffle. 所以我们可以安全地用 SpotInstance 来替换所有的 Task Node. 唯一的问题是,如果应 TaskNode 被回收,而 Task 需要从算,就会需要更多的时间。这时,你可以借助更多的 Spot Instance,利用更多的 Task Node 来加快整体的运行速度,比如说 4 个小时的运行时间,通过更多的 Task Node 把它加快到 1 小时运行,即因为一次从而导致需要 2 个小时,那么你在时间和成本上还是获得了改善。

我们一直都在提什么样的架构是好的软件架构,开发人员大都会想到:可伸缩、高可靠、可扩展、可复用、可维护。而实际上,在我做架构师的十多年经历当中,我发现其实除了以上这些一个让企业支付得起、并且能够让企业获得更高利润的架构,才是一个好架构。

